Elasticsearch 到 Elasticsearch
简述
Elasticsearch 是一款流行的搜索引擎,和关系型数据库、缓存数据库、实时数据仓库、消息中间件共同组成应用的现代化数据堆栈。
写入数据到 Elasticsearch 相对容易,但是如何将其数据实时同步出来,则要困难一些。
本文主要介绍如何通过 CloudCanal 结合 Elasticsearch 增量数据捕获插件,实现 Elasticsearch 到 Elasticsearch 数据迁移同步。
技术点
使用 Elasticsearch 插件机制
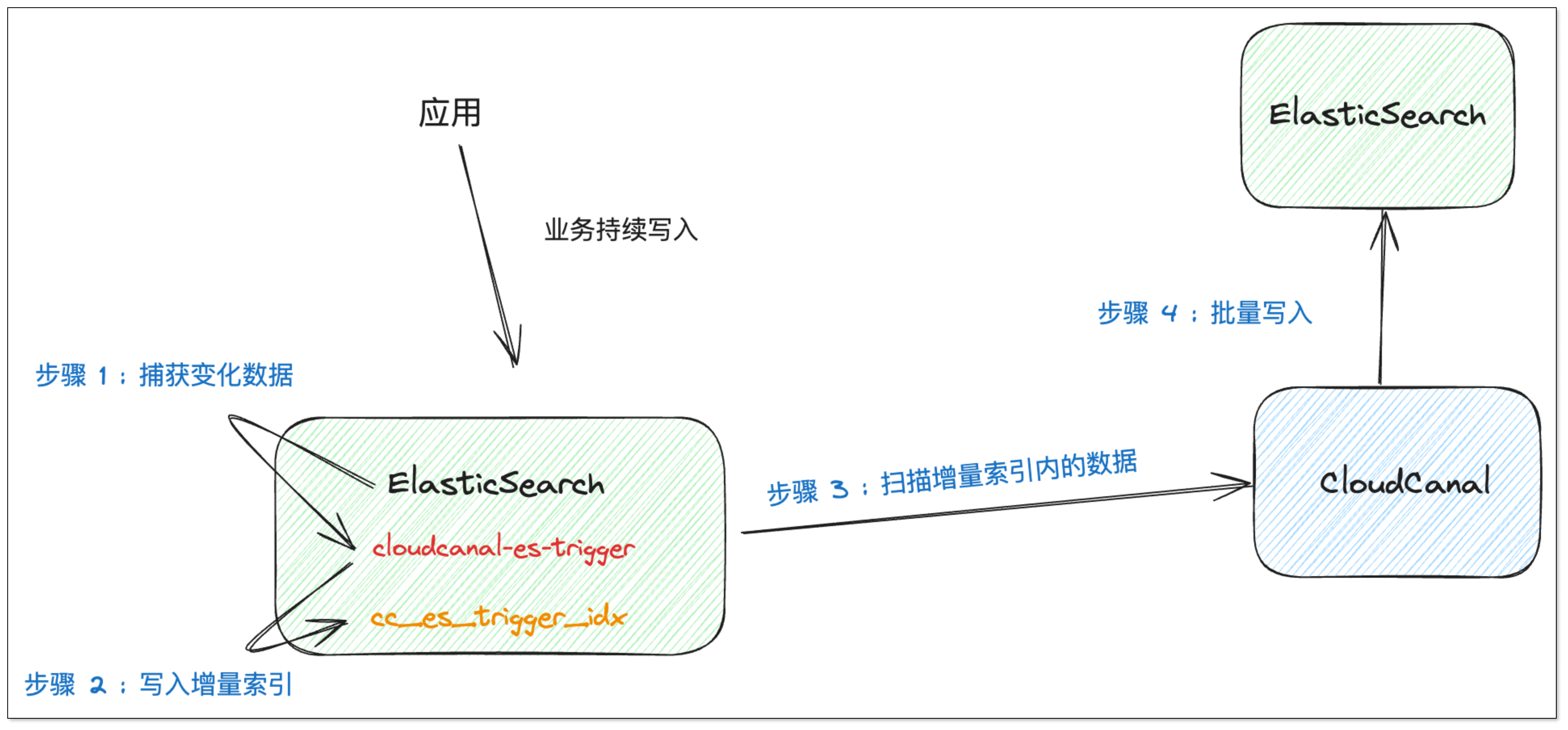
Elasticsearch 并没有明确给出如何实时获取其中的变更数据,但是其插件 API IndexingOperationListener 可订阅到 INDEX 事件和 DELETE 事件,前者即 INSERT 或 UPDATE 操作, 后者即传统意义上的 DELETE 操作。
明确增量数据的获取机制,如何让下游获取这些数据则成了接下来的问题。
我们采用了一个单独索引 cc_es_trigger_idx 作为增量数据的容器。
这个方式有几个好处:
- 不依赖第三方组件(如消息中间件)。
- Elasticsearch 索引管理方便。
- 和 CloudCanal 其他数据源 Trigger 方式增量数据获取风格一致,机制代码可重用。
索引 cc_es_trigger_idx 结构如下, 其中 row_data 保留 INDEX 操作变更后数据,pk 则保存文档 _id。
{
"mappings": {
"_doc": {
"properties": {
"create_time": {
"type": "date",
"format": "yyyy-MM-dd'T'HH:mm:ssSSS"
},
"event_type": {
"type": "text",
"analyzer": "standard"
},
"idx_name": {
"type": "text",
"analyzer": "standard"
},
"pk": {
"type": "text",
"analyzer": "standard"
},
"row_data": {
"type": "text",
"index": false
},
"scn": {
"type": "long"
}
}
}
}
}
Trigger 数据扫描机制
CloudCanal 使用 Elasticsearch 插件产生的增量数据,只要按照 cc_es_trigger_idx 索引 scn 字段顺序批量扫描消费即可。
消费代码风格和 SAP Hana 源端保持一致。
插件开源
Elasticsearch 插件加载会严格识别插件所依赖的三方包,如和 Elasticsearch 本体三方依赖包重复或版本不一致,则无法加载,所以插件需要和 Elasticsearch 版本保持一致(包括小版本)。
鉴于发布大量预编译包可操作性差,同时为了插件能够有更加广泛的使用,我们将插件开源在了 GitHub 上。
操作示例
步骤 1: 源端 Elasticsearch 安装插件
参考 Elasticsearch 源端同步准备 文档安装增量数据捕获插件。
步骤 2: 安装 CloudCanal
请参考 全新安装(Docker Linux/MacOS),下载安装 CloudCanal 私有部署版本。
步骤 3: 添加数据源
登录 CloudCanal 控制台 > 数据源管理 > 新增数据源 。
步骤 4: 创建任务
点击 同步任务 > 创建任务。
选择源和目标数据源,并分别点击 测试连接。
选择 数据同步 并勾选 全量初始化。
选择需要同步的索引。
选择索引对应的列。
信息如果需要选择同步的列,可先行在对端创建好索引即可。
点击 确认创建。
信息任务创建过程将会进行一系列操作,点击 同步设置 > 异步任务,找到任务的创建记录并点击 详情 即可查看。
Elasticsearch 源端的任务创建会有以下几个步骤:
- 结构迁移
- 初始化 ES 触发器和位点
- 分配任务执行机器
- 创建任务状态机
- 完成任务创建
等待任务自动流转。
信息当任务创建完成,CloudCanal 会自动进行任务流转,其中的步骤包括:
- 结构迁移: Elasticsearch 源端的索引映射定义将会迁移到对端,如果同名索引在对端已经存在,则会忽略。
- 全量数据迁移: 已存在的存量数据将会完整迁移到对端。
- 增量数据同步: 增量数据将会持续地同步到对端数据库,并且保持实时(秒级别延迟)。
总结
本文简单介绍了如何使用 CloudCanal 进行 Elasticsearch 到 Elasticsearch 数据迁移同步。
Elasticsearch 作为现代数据应用的重要组成部分,通过 CloudCanal 数据迁移同步加持,让数据进出更加便利和顺畅。