MySQL 到 MySQL
简述
MySQL 到 MySQL 在线数据迁移同步不是一个新鲜话题了,但是面对数据源异构、高度产品化创建、并且稳定运行于在线严苛场景,需要做的工作会比一个单纯工具或者脚本多得多。
本篇文章仅从功能角度介绍 CloudCanal 如何快速创建并运行此种数据链路。
技术点
"异构"和面临的问题
数据库异构主要体现在 数据库差异、业务表结构约束差异和 业务数据差异 三个方面。后两者属于传统 ETL Transform 阶段要处理的内容,相对弹性。而数据库本身差异则是刚性需求,对产品架构和核心数据结构有较高要求,分解下原因,包括 增量数据获取方式多样、SQL 方言差异、约束差异、元数据差异、部署形态(如分布式)等。
增量数据获取方式
如 ORACLE 的 redo 日志、物化视图,MySQL binlog 、Postgres WAL、MongoDB oplog等,相差较大,系统级设计和抽象,也是一个漫长的过程。
SQL 方言差异
包含如数据分页差异、写入冲突处理、大小写处理、表结构差异等。
约束差异
如索引 owner 归属偏差、partition key/sharding key 和 PK/UK 关系差异等。上述两者,对于数据迁移同步影响较小,但是 DDL 同步、结构迁移存在巨大挑战,在库、表、列映射、裁剪,数据自定义处理等情况下,更加复杂。
元数据差异
包括数据类型转换、层次对应关系、partition key / sharding key 等特定结构支持、分布式数据库分片差异、缓存/消息等schemaless系统的挑战,让数据互融互通工作量大增。
但是今天,我们并不展开介绍 数据库类型不同 的数据迁移同步功能,而是介绍 MySQL 到 MySQL 在线数据迁移同步所面临的异构问题,更多是业务需求所产生的 表结构不一致和 数据差异,其中包括库、表、列映射、裁剪 和 数据过滤。希望此篇文章能够让你在 5 分钟内搞定这个事情(环境 ready 的情况下)。
举个"栗子"
准备 CloudCanal
- 下载安装 CloudCanal 私有部署版本,使用参见快速上手文档
数据库准备
- 创建 3个 MySQL 数据库,源实例上的库叫 drds_1 和 drds_2 ,目标实例上有 drds_merge 库,其中源库里面有若干张表,并且存在一些测试数据,有些表正常迁移(worker_stats表), 有些表需要汇聚(shard_x表),有些表需要结构迁移(kbs_question),有些表有映射(shard_x表),有些表不同步(kbs_article表),有些表字段需要映射和裁剪(data_job)。接下来我们花 5 分钟时间来搞定这个事情,并且做一次数据校验。
订阅源端MySQL增量和全量,需要提前授予权限:select, replication_client, replication_slave
造些数据
启动源端造增量数据程序,IUD 比例 30:50:20
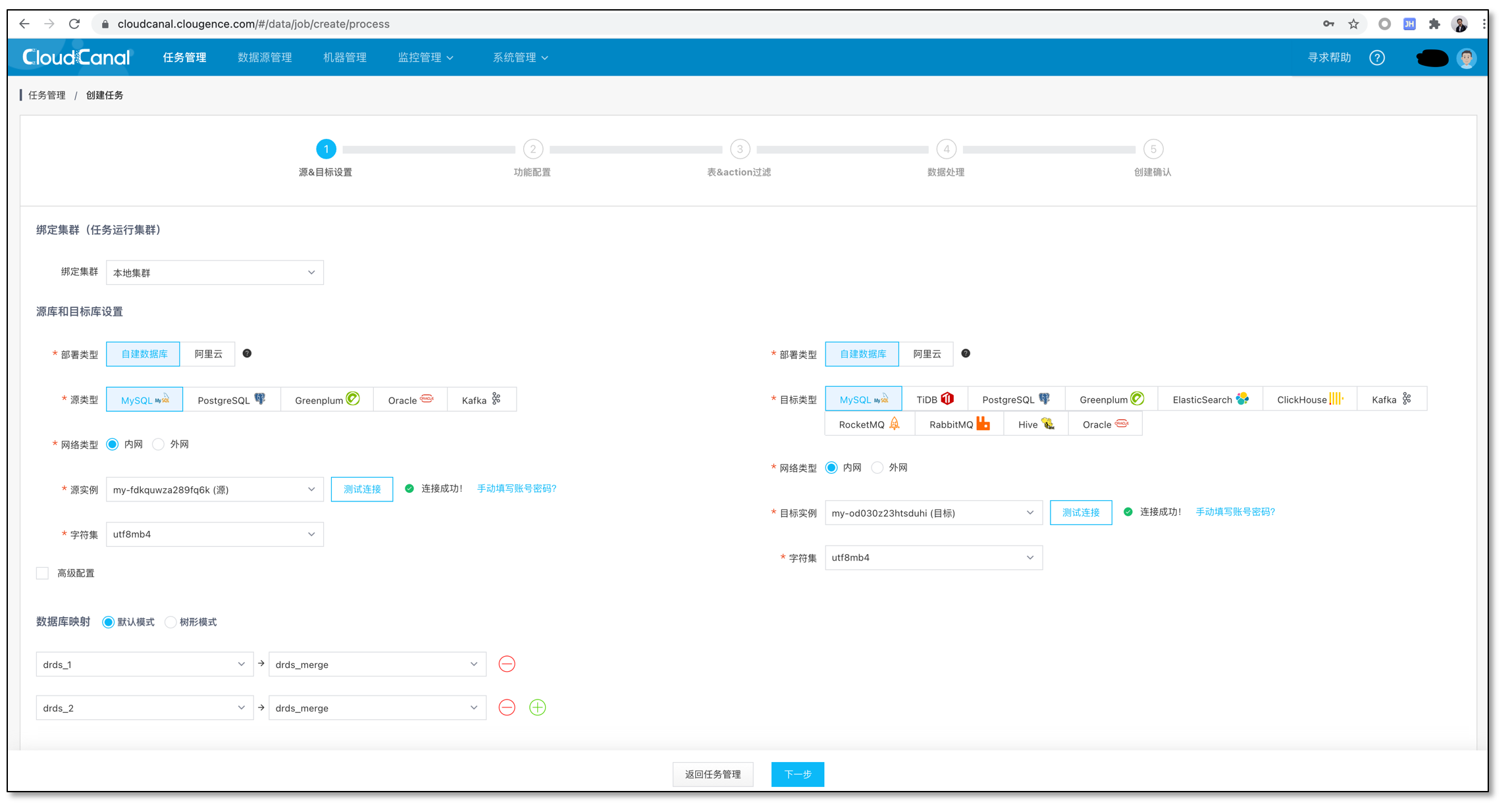
创建任务
选择源数据库和目标数据库,做好库映射。操作完毕点击下一步。
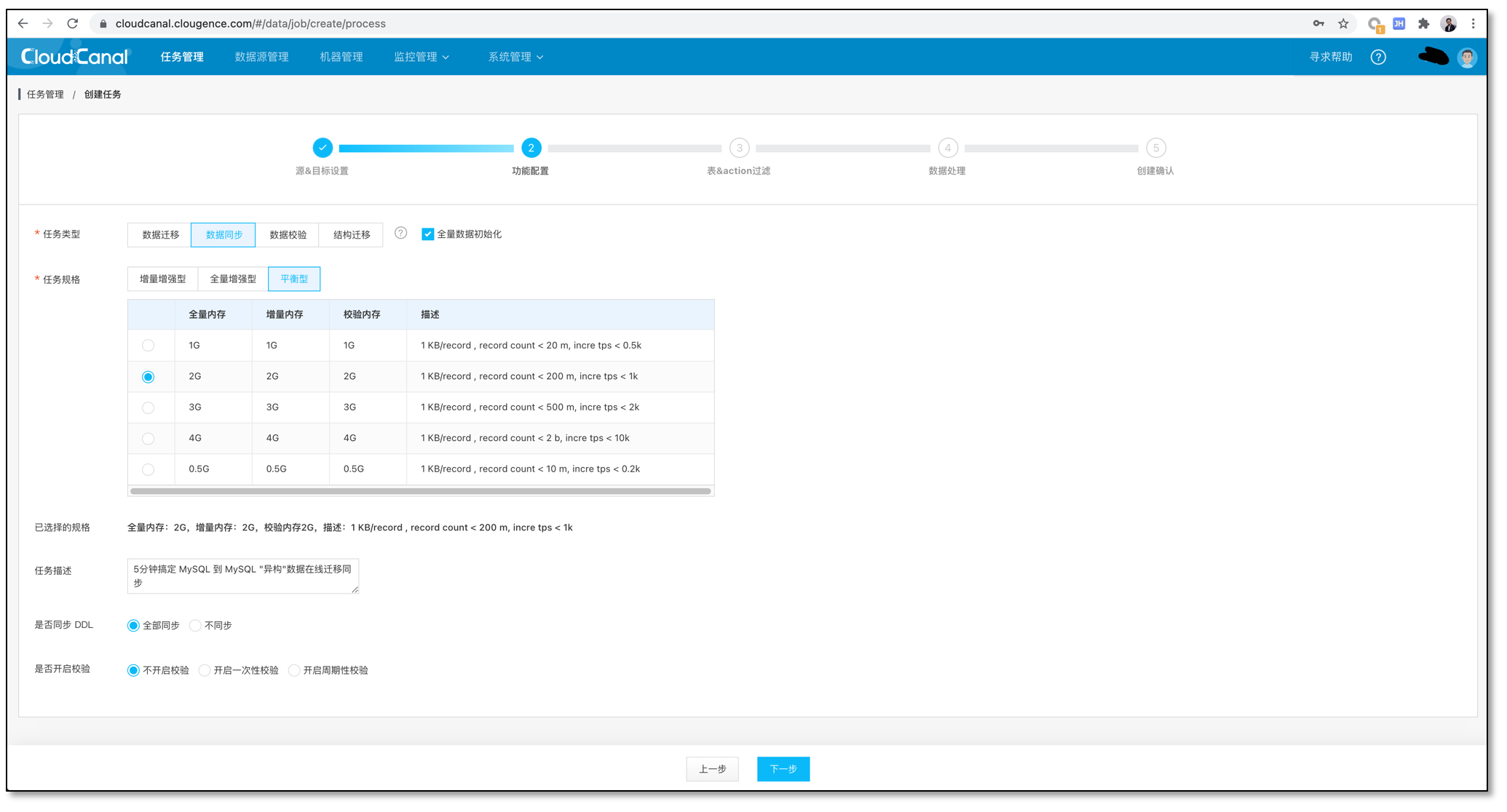
选择数据同步,并默认勾选数据初始化、DDL 同步,此处暂不勾选做一次性数据校验。在任务增量追上后,我们停掉造数据程序,创建逻辑一致的校验任务,那么结果更加清晰。
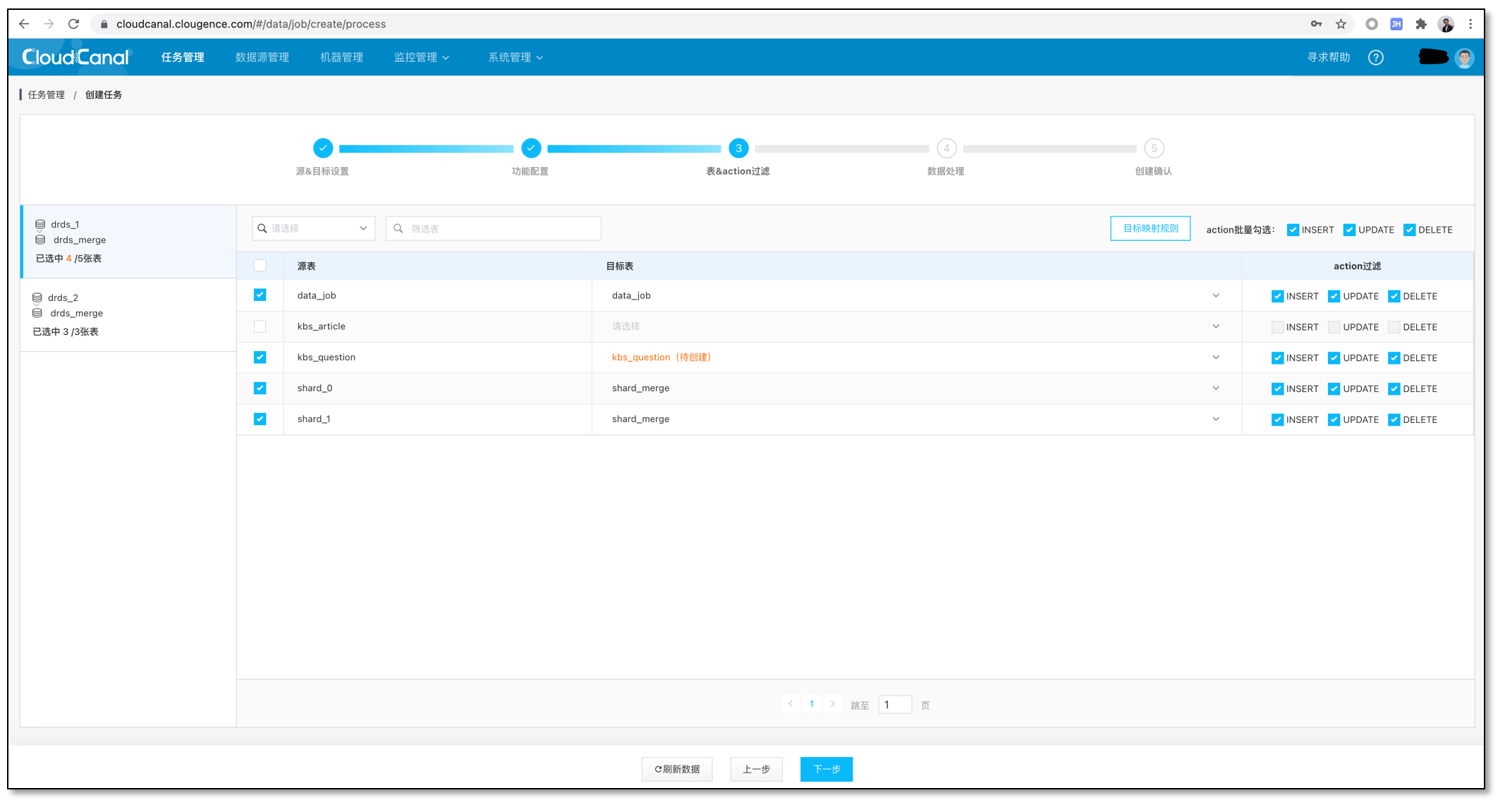
选择表,并做好表映射,以及去除不想迁移同步的表。操作完毕点击下一步。
选择列,并做好列映射、裁剪掉某些不需要表的列。
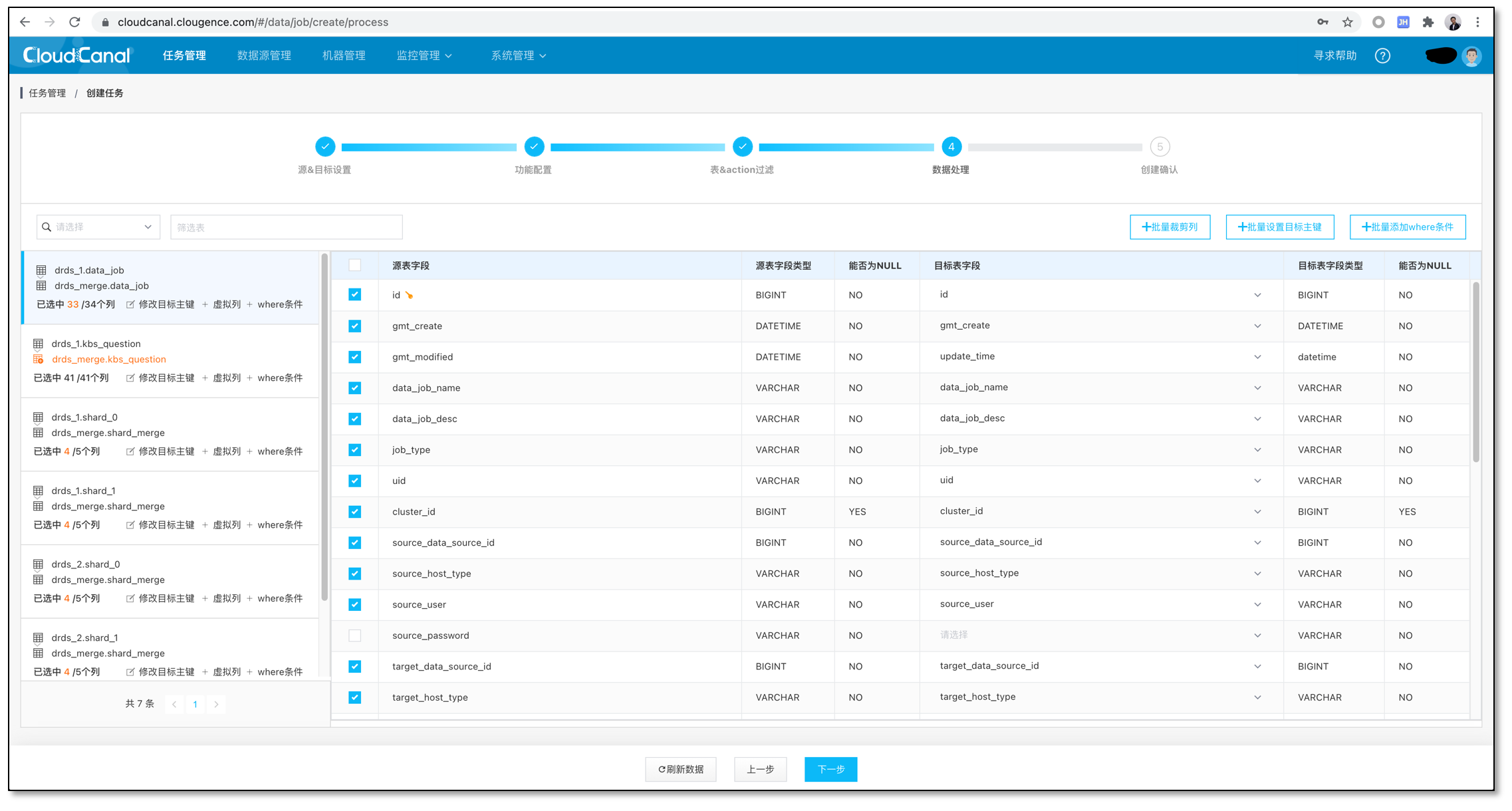
批量设置唯一键为主键。
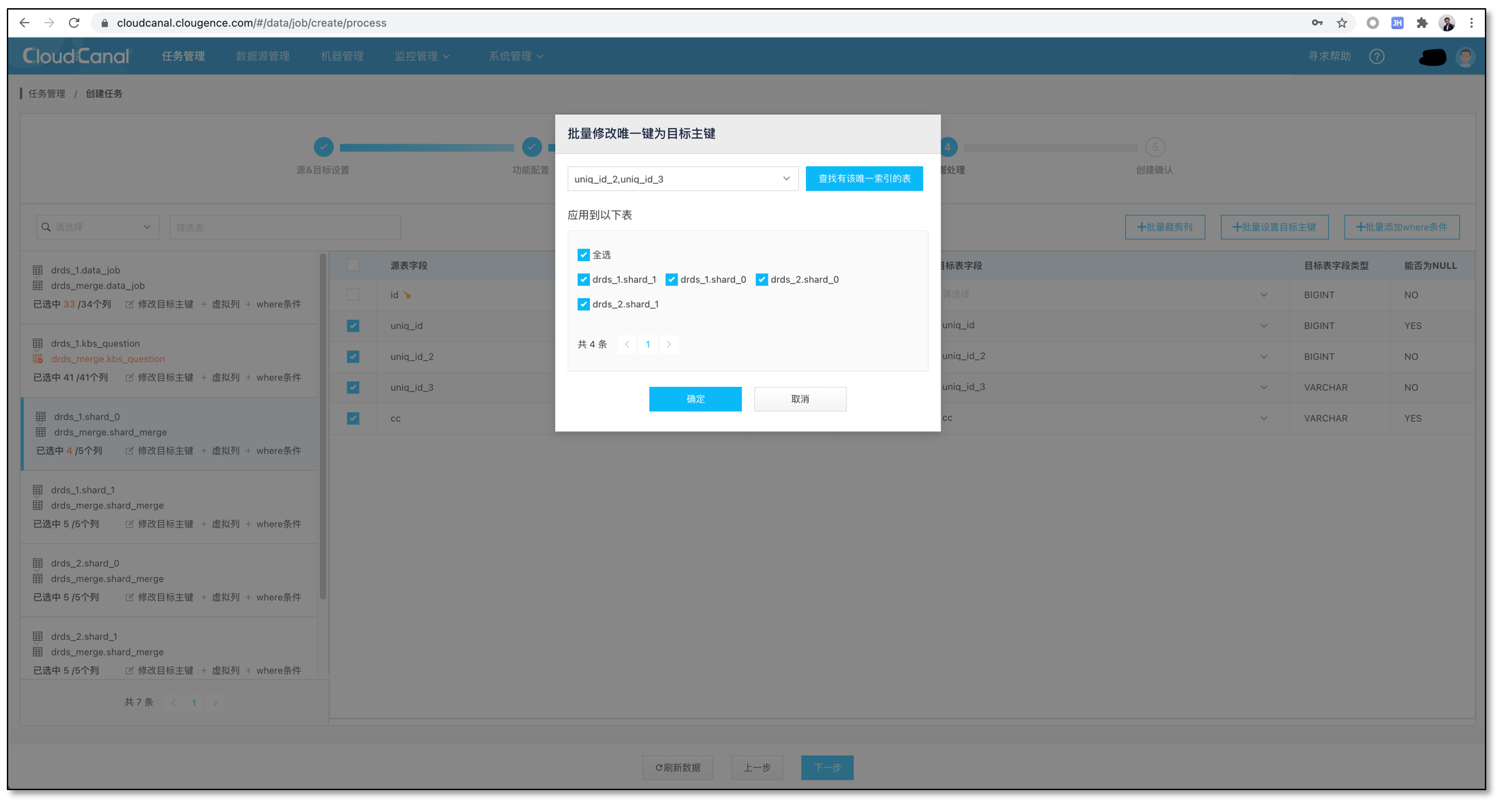
设置数据过滤,如图中 id < 3000。操作完毕点击下一步。
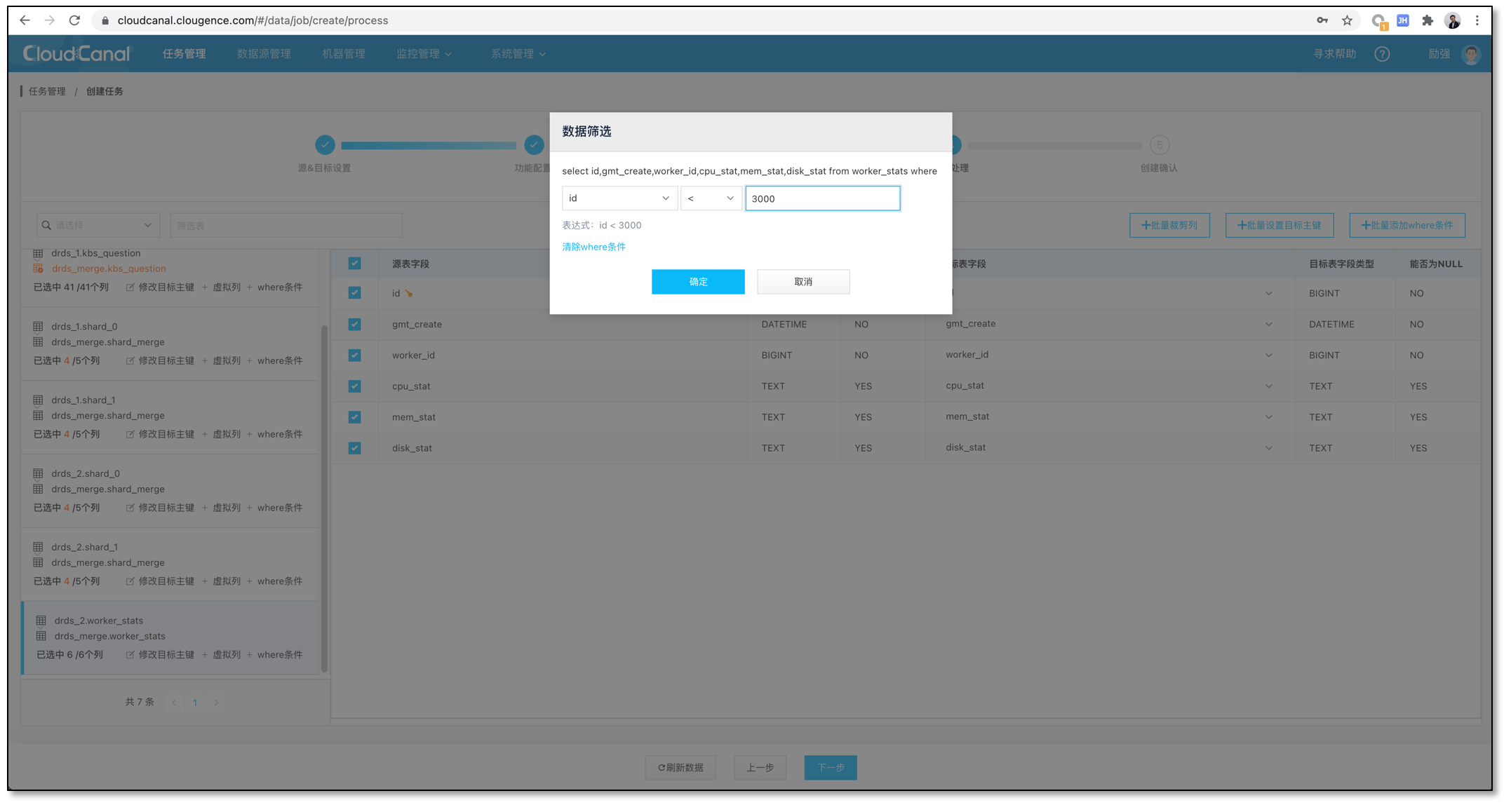
确认创建任务。确认完毕点击创建任务。
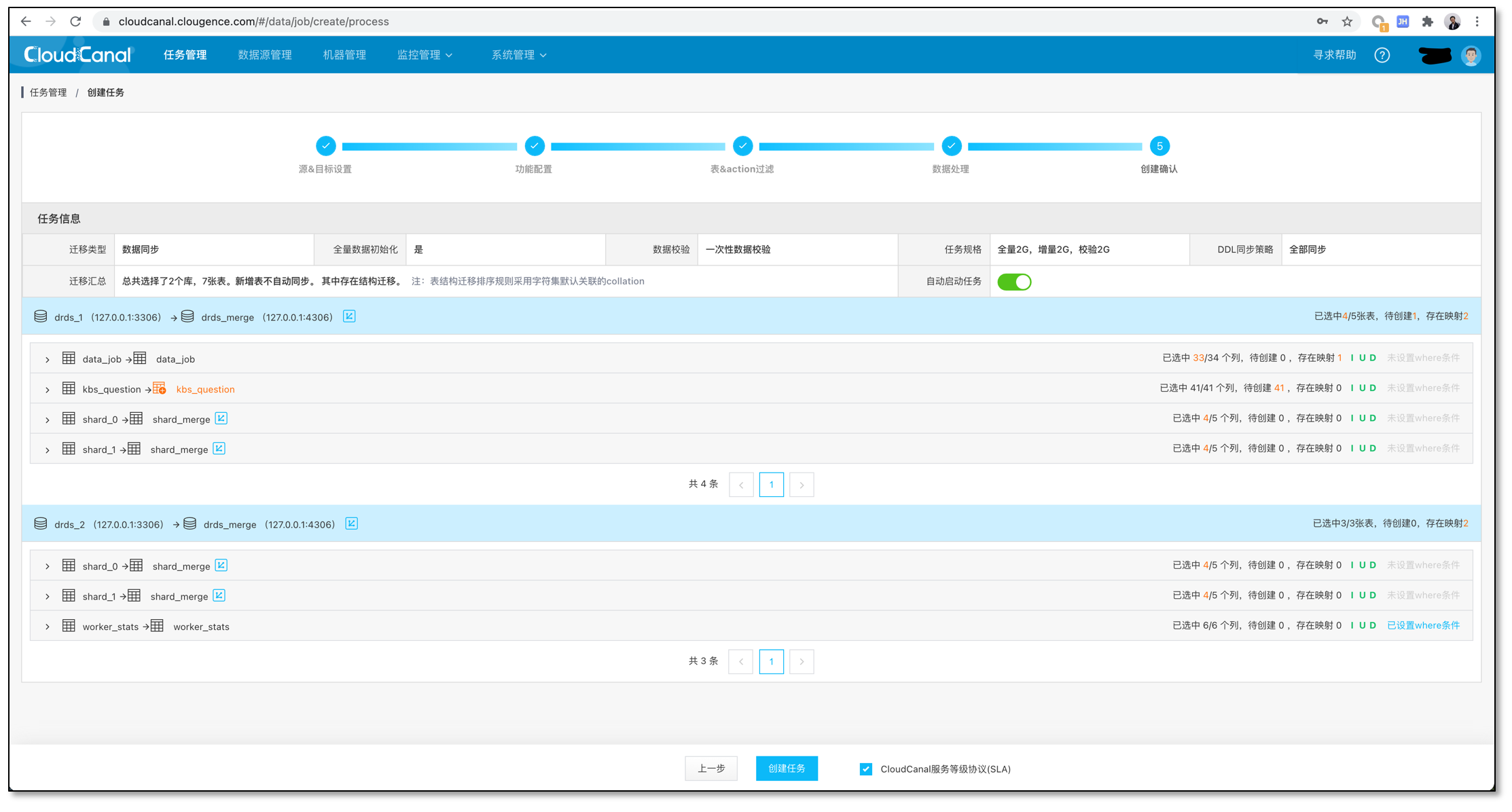
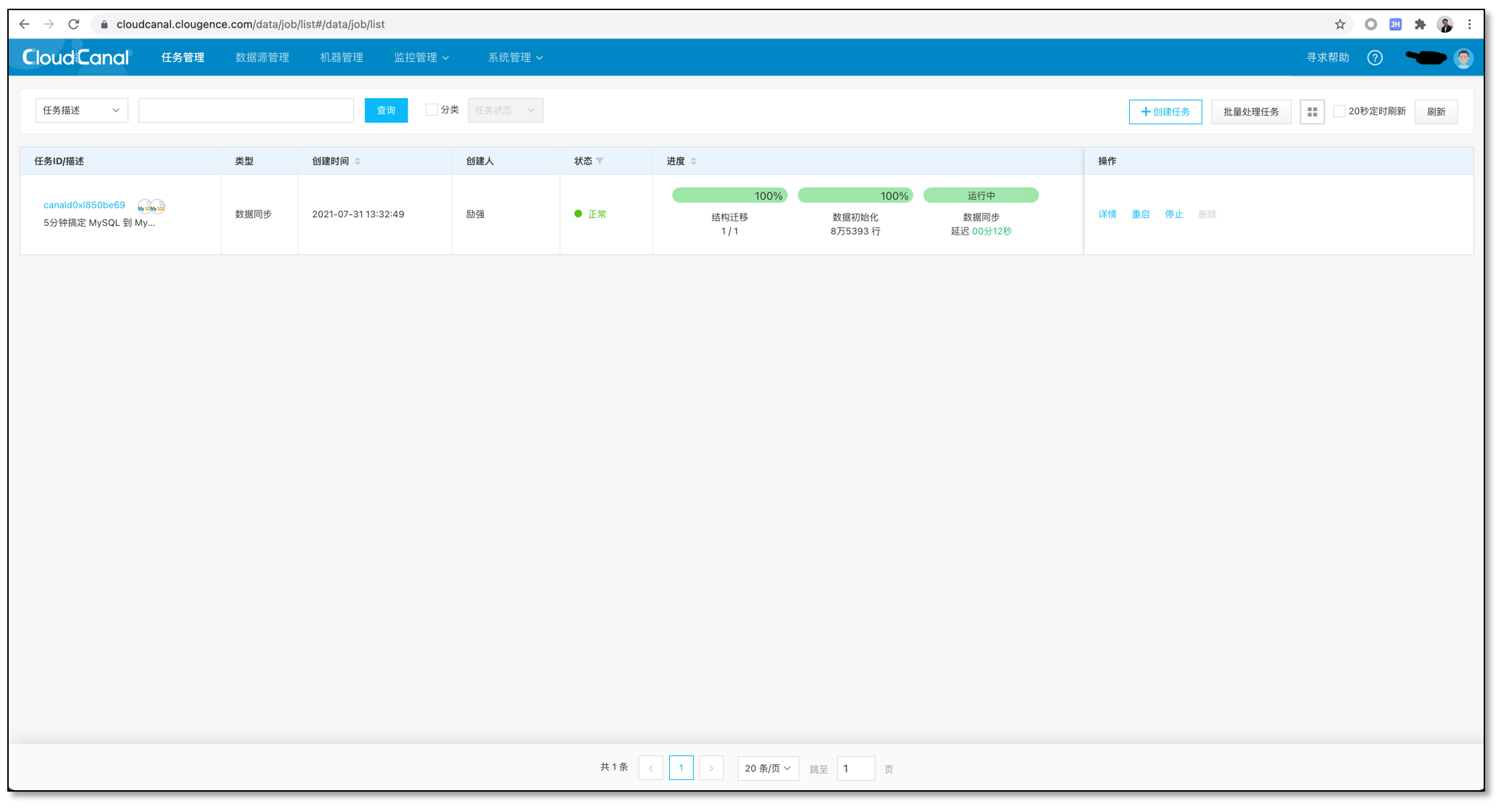
任务运行
如果选择的库、表、列在对端不存在,则进行结构迁移
结构迁移完成后自动进行数据初始化,映射、裁剪、数据过滤按照设定运行。目前 CloudCanal 数据初始化都是逻辑初始化,速度可能没有某些物理初始化快,但是灵活度高。
数据初始化完毕,开始进行增量同步。增量同步会自动从数据初始化位点拉取 MySQL binlog 进行回放,同样会执行映射、裁剪、以及数据过滤等操作。
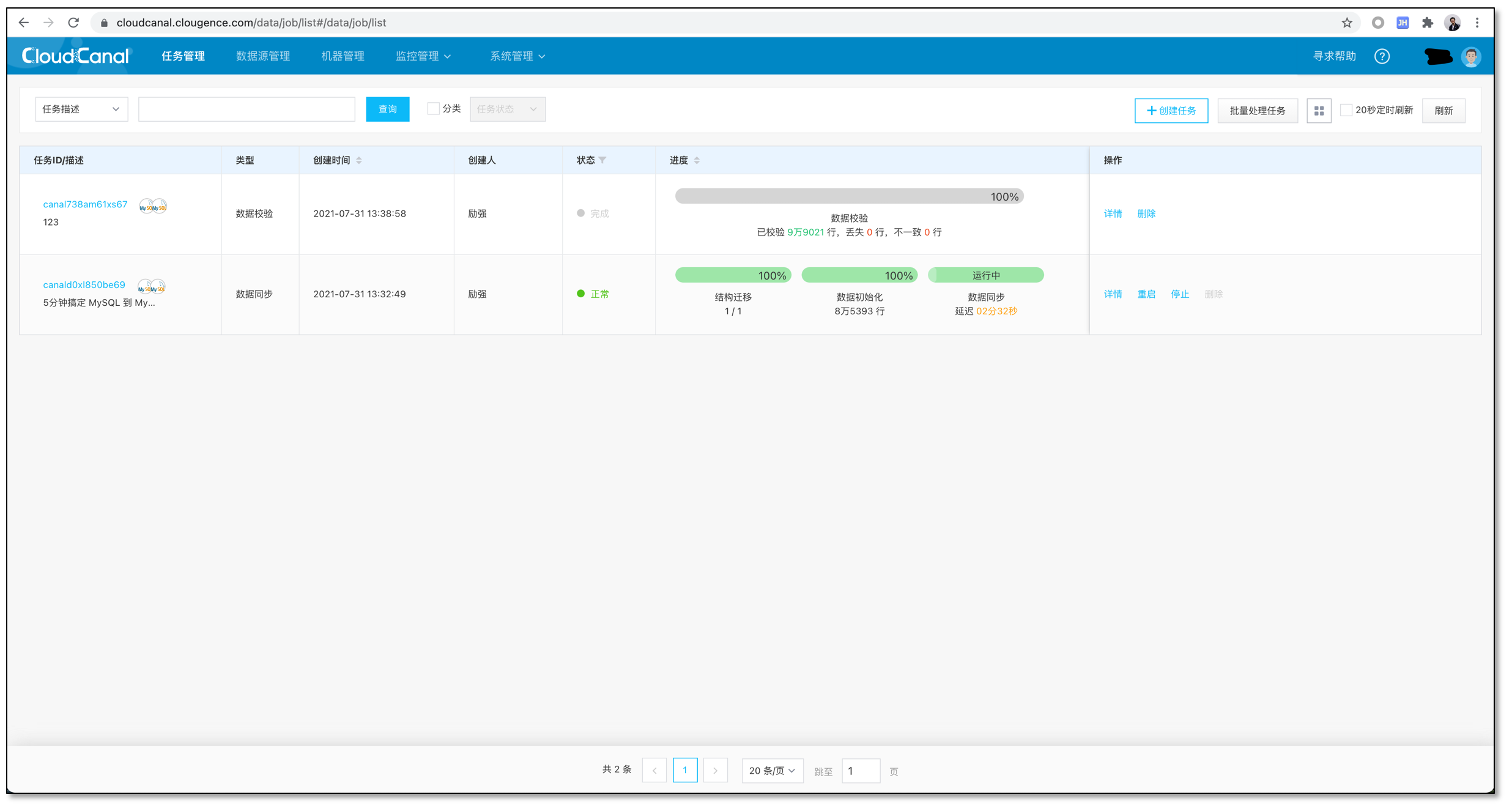
数据校验
停止造数据进程,并且在 CloudCanal 上按同步任务相同逻辑创建一个校验任务。(暂未推出创建相似任务)
校验任务跑完,获取差异数据,并抽样对比,数据一致。校验的差异主要是数据多次更新、同步延迟等造成,一般非大规模不一致或丢失,则数据正常。
数据差异数据目前需要到任务日志目录获取,暂时未提供日志下载能力。
总结
此篇文章主要从功能角度简单介绍 CloudCanal 支持 MySQL 到 MySQL 在线数据迁移同步,包含库、表、列白名单、映射、裁剪,分表汇聚,数据过滤等主要能力,对于在线大部分场景,能够较好满足,但是在严苛的核心场景上,监控告警、容灾、特殊数据处理、抗峰值、问题快速排查等都是不可缺少的。